Simpler queries for the 2.5B transcriptional profiles of the Arc Virtual Cell Atlas  ¶
¶
With 2.5B expression profiles that map to about 600M cells, the Arc Virtual Cell Atlas offers the world’s largest collection of uniformly processed scRNA-seq datasets. Arc Institute distributes the atlas as 460k parquet and h5ad files totaling 41TB on Google Cloud Storage. We present a database mirror that offers queries by entities, a graphical user interface, and zero-copy, lineage-aware sharing of datasets.
For example, you might want to find datasets for human brain samples linked to glioblastoma that were processed with a certain pipeline. In the original atlas,[1] this requires scanning directories and parquet files. In a database, you can express queries through the entities you care about: the organism, tissue, disease, and the processing pipeline. The screenshot shows how this works on lamin.ai/laminlabs/arc-virtual-cell-atlas:
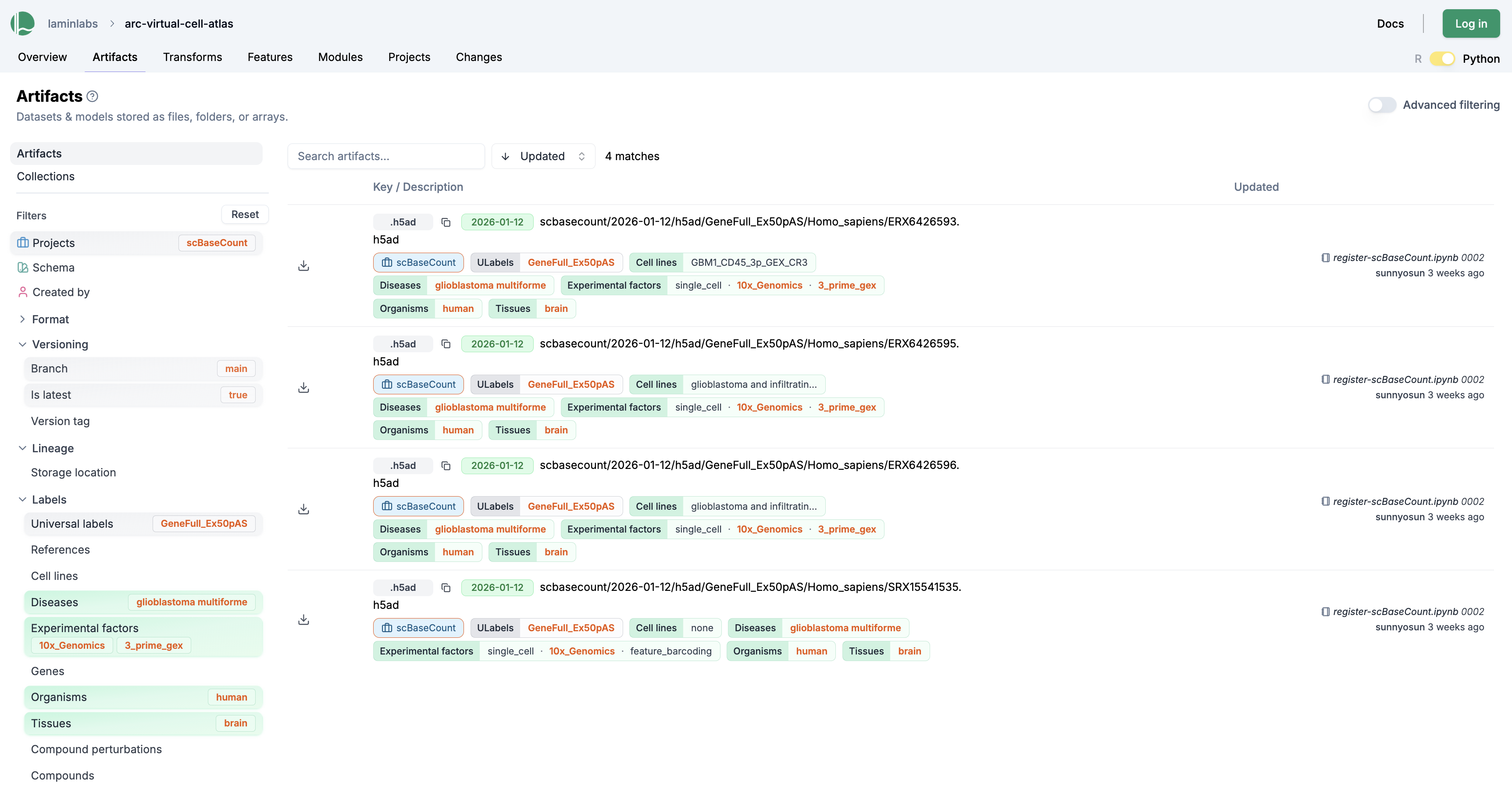
The same query can also be expressed in Python or R:
import lamindb as ln
db = ln.DB("laminlabs/arc-virtual-cell-atlas")
scbase = db.Project.get(name="scBaseCount")
gbm = db.bionty.Disease.get(name="glioblastoma multiforme")
brain = db.bionty.Tissue.get(name="brain")
human = db.bionty.Organism.get(name="human")
factors = db.bionty.ExperimentalFactor.filter(name__in=["10x_Genomics", "3_prime_gex"])
genefull = db.ULabel.get(name="GeneFull_Ex50pAS")
datasets = db.Artifact.filter(
projects=scbase,
diseases=gbm,
tissues=brain,
organisms=human,
experimental_factors__in=factors,
ulabels=genefull,
is_latest=True,
)
library(laminr)
ln <- laminr::import_module("lamindb")
db <- ln$DB("laminlabs/arc-virtual-cell-atlas")
scbase <- db$Project$get(name = "scBaseCount")
gbm <- db$bionty$Disease$get(name = "glioblastoma multiforme")
brain <- db$bionty$Tissue$get(name = "brain")
human <- db$bionty$Organism$get(name = "human")
factors <- db$bionty$ExperimentalFactor$filter(name__in = c("10x_Genomics", "3_prime_gex"))
genefull <- db$ULabel$get(name = "GeneFull_Ex50pAS")
datasets <- db$Artifact$filter(
projects = scbase,
diseases = gbm,
tissues = brain,
organisms = human,
experimental_factors__in = factors,
ulabels = genefull,
is_latest = TRUE
)
Queried datasets can then be transferred, loaded, cached, or streamed for cell-level slicing:
first_dataset = datasets[0]
first_dataset.save() # zero-copy transfer into your own database
adata = first_dataset.load() # cache and load into memory
local_filepath = first_dataset.cache() # cache and return file path
with first_dataset.open() as adata: # stream slices from cloud storage
...
first_dataset <- datasets[[1]]
first_dataset$save() # zero-copy transfer into your own database
adata <- first_dataset$load() # cache and load into memory
local_filepath <- first_dataset$cache() # cache and return file path
with(first_dataset$open(), { # stream slices from cloud storage
...
})
Under the hood, these methods preserve a run object that points back to the original dataset in the Arc database so that downstream processing can be traced back to the source.
For example, here we used the .save() method to sync the Tahoe-100M datasets into a database for benchmarking different ML data loaders:
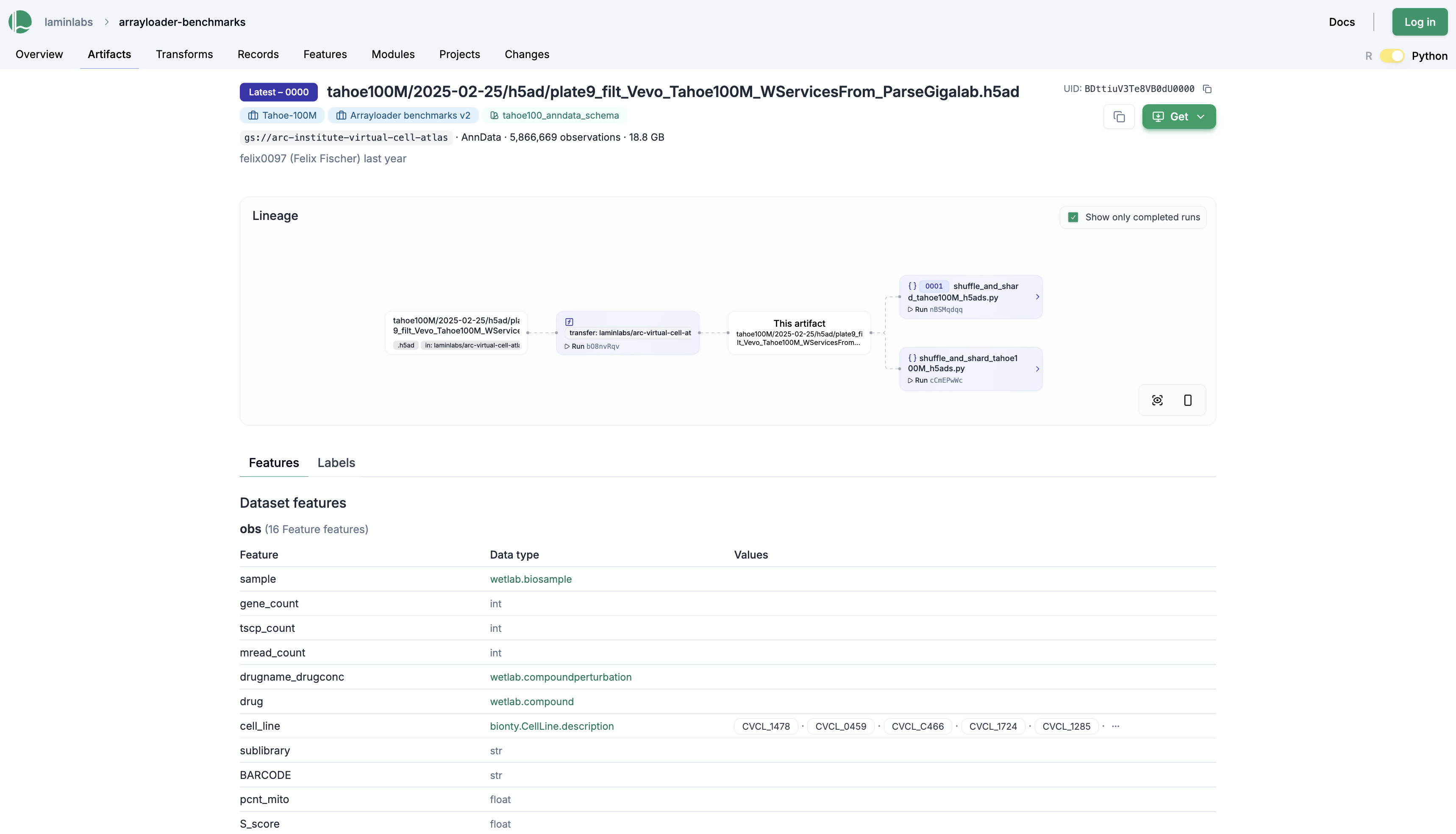
By applying fast data loaders such as annbatch[2] or scdataset[3] to locally cached arrays, one can achieve loading times of 50k - 80k vectors/second. Here is an example for such a data loading run.
For a detailed walk-through, read the tutorial: docs.lamin.ai/arc-virtual-cell-atlas.
Entities¶
The database is organized around entity types that are familiar from single-cell analysis workflows. In LaminDB, these entity types map to biological ontologies and experimental registries through an adaptation of the Django ORM. You can explore them on the UI and in the API reference:
Entity (click to explore) |
Examples |
Source |
|---|---|---|
|
Sample / study metadata |
|
|
Sample metadata |
|
study-level disease annotations |
Sample metadata (see Arc note on study-level disease) |
|
Cellosaurus IDs, common names |
scBaseCount sample fields; Tahoe |
|
single-cell vs nucleus, 10x chemistry, … |
|
|
compounds, concentrations |
|
|
|
Dataset program |
|
|
||
|
scBaseCount release folder |
Releases¶
The Arc Virtual Cell Atlas combines two major data resources: Tahoe-100M[4] and scBaseCount.[1] scBaseCount comes with two releases, which we mirror. You can use the version_tag to select a release or keep the default of is_latest=True to select the latest release. For Tahoe-100M, the latest release is 2025-02-25.
|
Arc release |
Scale |
|---|---|---|
|
Publication release (current) |
>502M cells, 27 organisms, 5 STARsolo count features |
|
>230M cells, 21 organisms |
Other atlases¶
laminlabs/arc-virtual-cell-atlas exists alongside laminlabs/cellxgene, laminlabs/hubmap, and other public atlases mirrored as LaminDB instances at lamin.ai/explore, allowing the same query patterns to be reused across multiple resources.
Code & data availability¶
Acknowledgements¶
We’re grateful to the creators of the original resource[1][4] for sharing it publicly on a scalable storage backend. We’re particularly grateful to Nicholas Youngblut for helping with questions regarding the structure of the atlas and reviewing the tutorial.
How to cite¶
Please cite the original references! If the mirror is useful to you, consider citing:
Sun S, Rybakov S, Enard F, Sriworarat C & Wolf A (2026). Simpler queries for the 2.5B transcriptional profiles of the Arc Virtual Cell Atlas. Lamin Blog. https://blog.lamin.ai/arc-virtual-cell-atlas